Improving Reasoning with
Inference-Time Scaling
Making AI 3× Better at Math Without Retraining
What Are Reasoning Models?
The Challenge: Teaching AI to Think Step-by-Step
Reasoning Models are LLMs that can:
- Break down complex problems into steps
- Show their work (like a student showing math calculations)
- Verify their own answers
- Think through multiple solution paths
Examples:
OpenAI o1 • Google Gemini • DeepSeek R1 • Claude Sonnet
The Problem & Our Goal
MATH-500 Benchmark
Dataset: 500 challenging math problems from high school competitions
- Algebra, calculus, geometry, number theory
- Requires multi-step reasoning
- Correct answer must be extracted from model output
Our Baseline:
- Model: Qwen3-0.6B (pre-trained base model)
- Performance: 15.2% accuracy
- Problem: This is not good enough for real-world use!
Can we improve this WITHOUT retraining the model?
What is Inference-Time Scaling?
Improving Performance During Generation
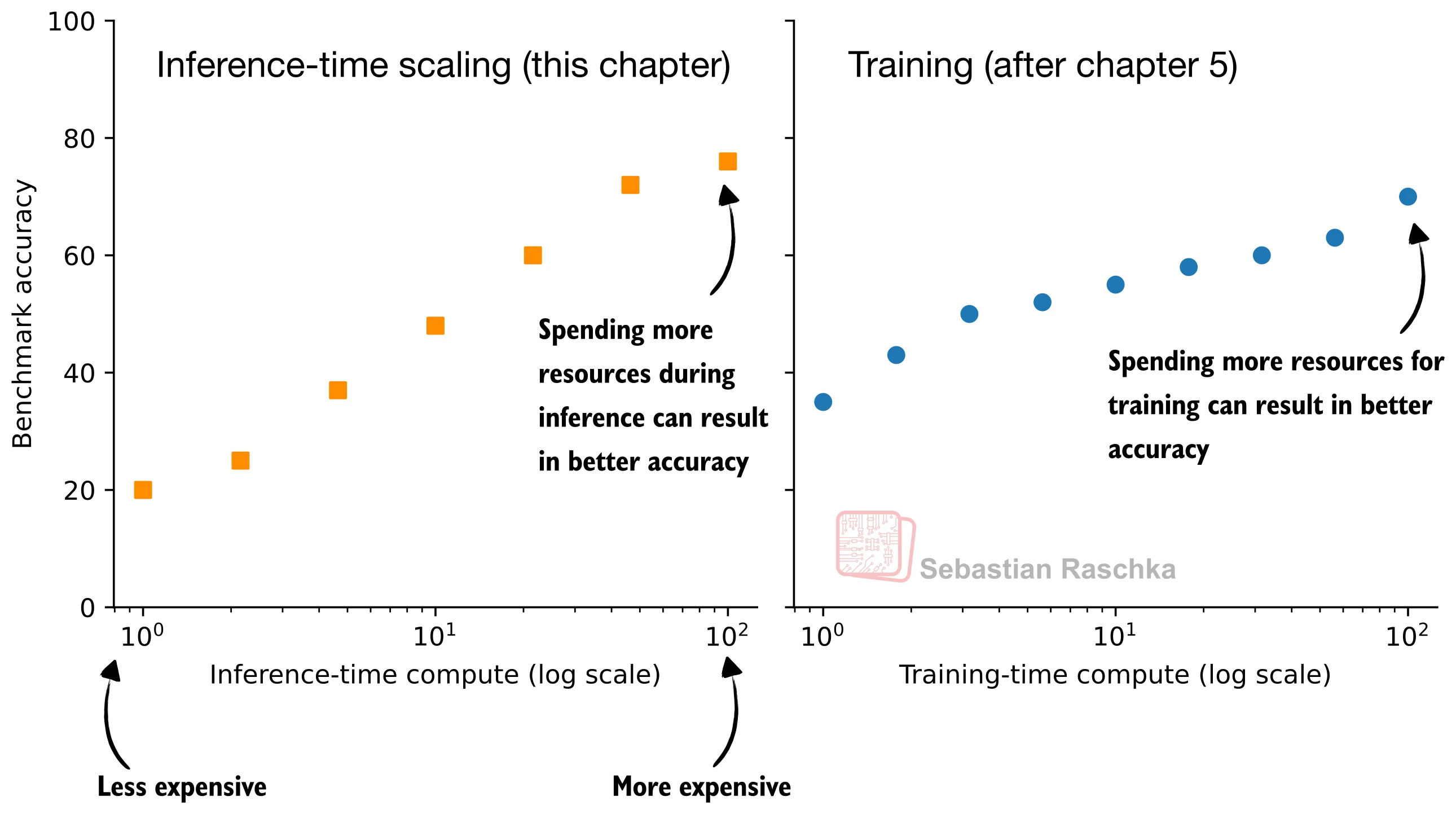
Key Idea: Use more compute during inference to get better results
Three Methods in This Book
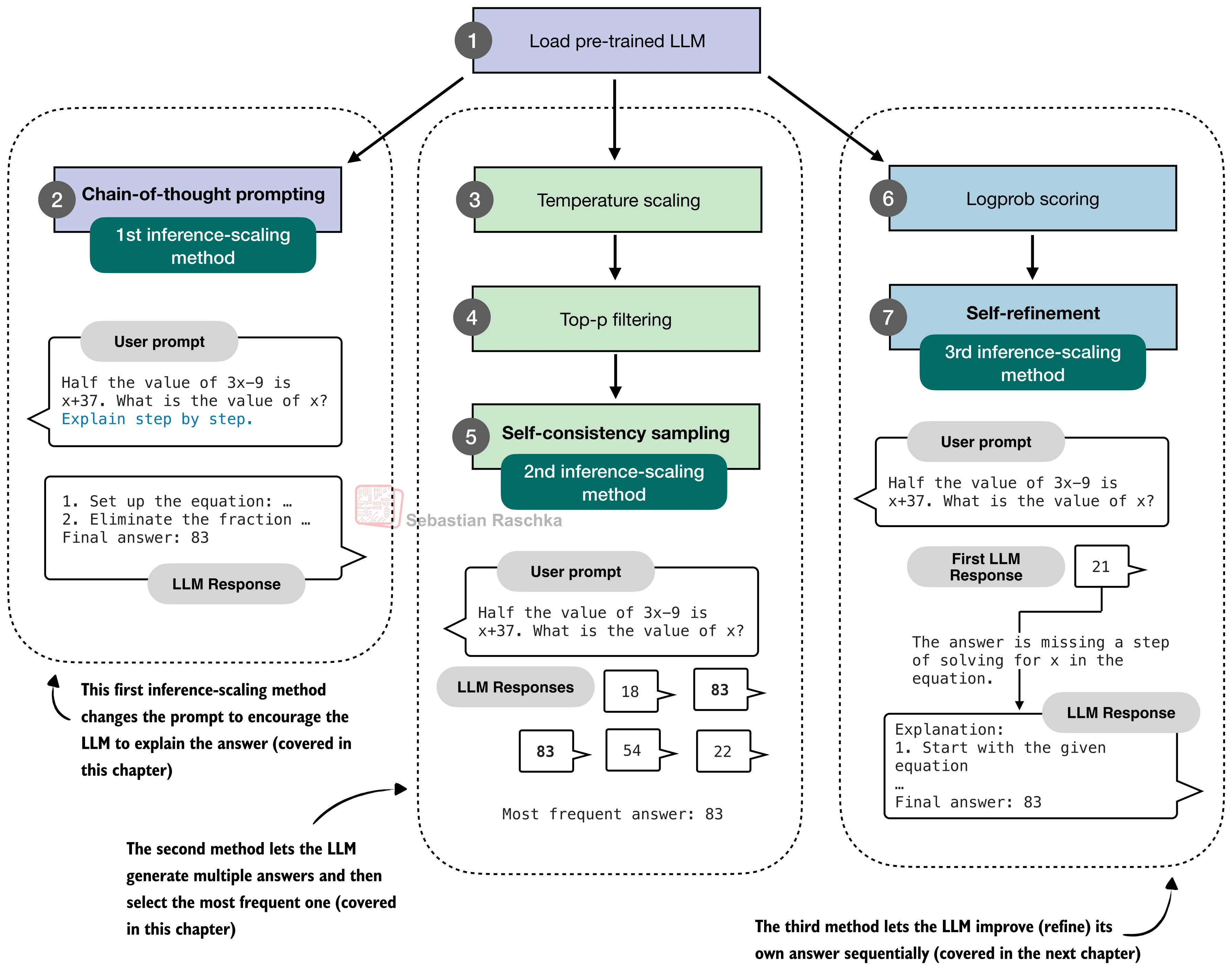
- Self-consistency (This chapter)
- Verifier-based sampling (This chapter)
- Self-refinement (Next chapter)
All three methods more than DOUBLE the baseline accuracy!
Baseline Example - Why It Fails
Problem:
"Half the value of $3x-9$ is $x+37$. What is the value of $x$?"
Baseline Model Output:
\boxed{10}Correct Answer: 83
What Went Wrong?
- Model jumped directly to an answer
- No intermediate steps shown
- No verification of the math
- Just a guess based on pattern matching
Technique 1: Chain-of-Thought Prompting
The Simplest Fix: Just Ask It to Think!

The Modification:
# Original prompt
prompt = "Question: ... What is the value of x?\nAnswer:"
# Chain-of-Thought prompt
prompt_cot = prompt + "\n\nExplain step by step."That's it! Just adding "Explain step by step."
Chain-of-Thought Results
Model Output with CoT:
To solve the problem, we need to find the value of x...
Step 1: Set up the equation
1/2(3x - 9) = x + 37
Step 2: Eliminate the fraction
Multiply both sides by 2:
3x - 9 = 2x + 74
Step 3: Solve for x
Subtract 2x from both sides:
x - 9 = 74
Add 9 to both sides:
x = 83
Final Answer: \boxed{83}✓ Correct!
Accuracy on MATH-500:
15.2% → 40.6% (+167% improvement!)
Problem with Deterministic Decoding
We're Stuck with One Answer
Current Approach: Greedy decoding
- Always pick the most probable next token
- Same input → Same output (deterministic)
- If the model makes an early mistake, it's stuck on that path
What if we could explore multiple reasoning paths?
How LLMs Select the Next Token
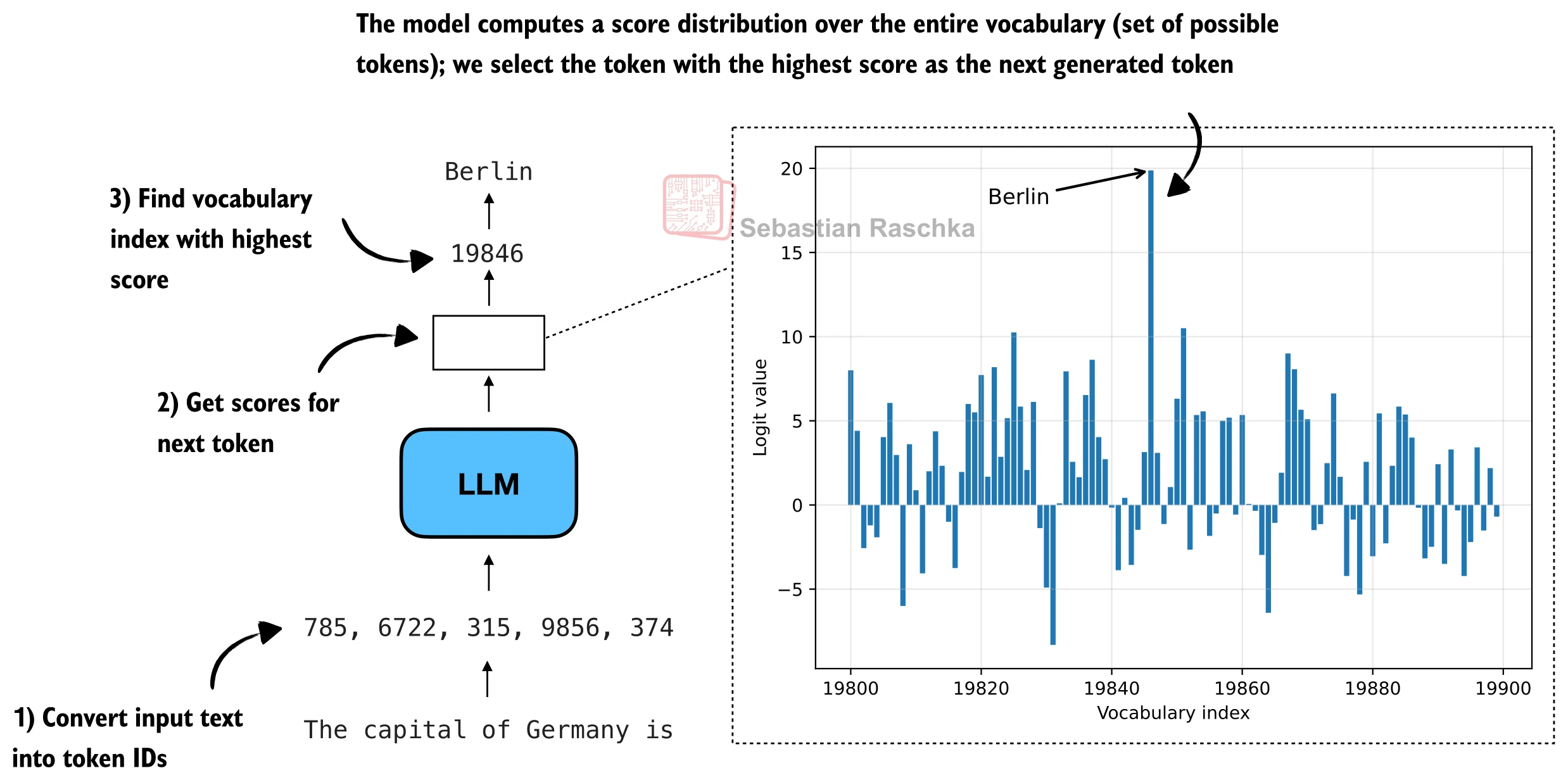
The Process:
- Input text → Tokenize → Token IDs
- Model forward pass → Logits (scores for each vocab token)
- Selection → Pick token with highest score (argmax)
- Decode → Convert token ID back to text
Visualizing Token Scores
For "The capital of Germany is ___"
│
│ ▂
│ ▂█▂
│ ▂███▂
│ ▂█████▂
│ ▂███████▂▂
│ ▂▂█████████▂▂
└────────────────────→
19800 19846 19900
↑
"Berlin"
Key Points:
- Most tokens have very low scores
- A few tokens (Berlin, Munich, Hamburg) have high scores
- Greedy decoding always picks "Berlin" (the peak)
Temperature Scaling
Rescaling Logits to Control Randomness
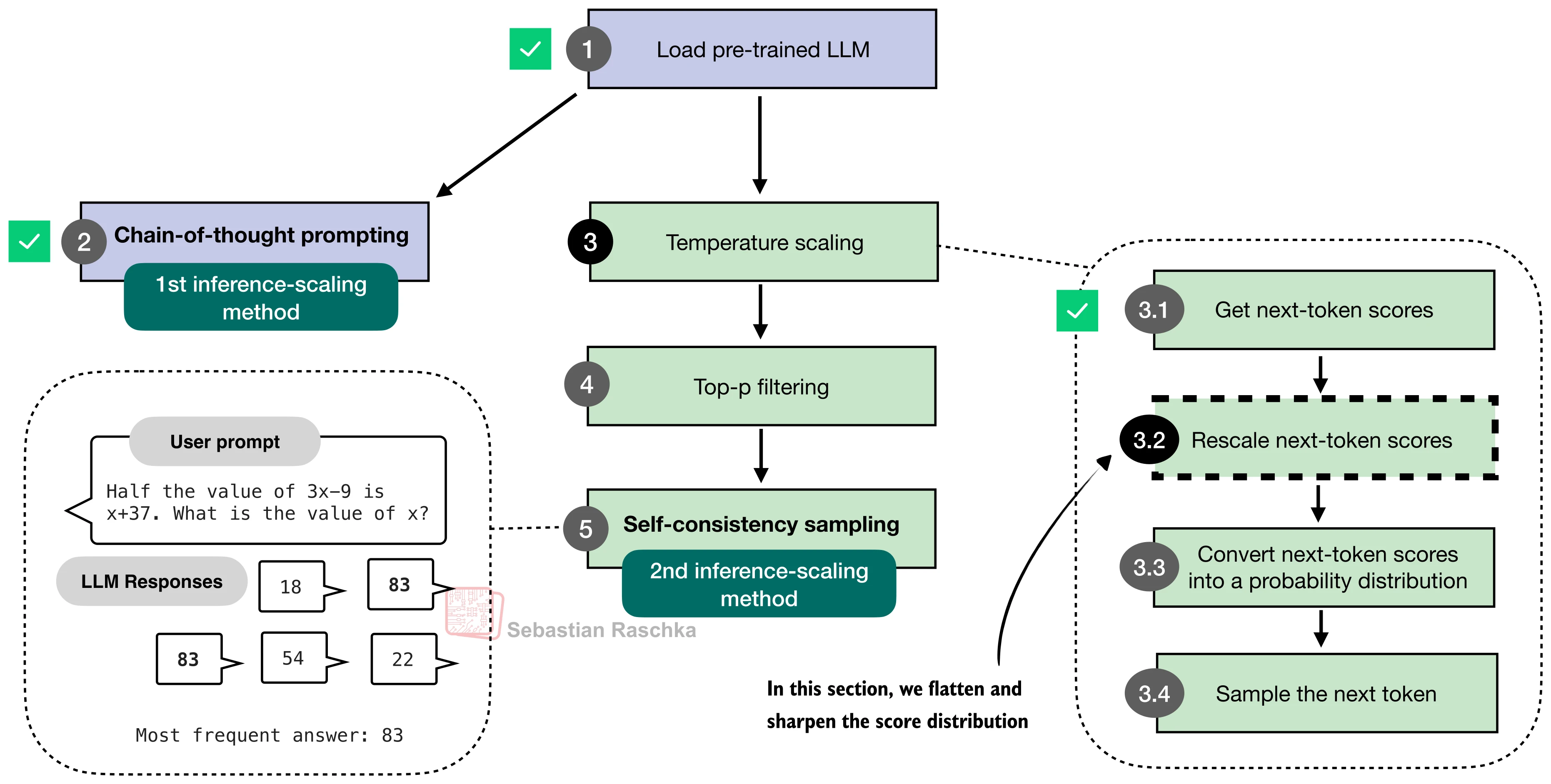
def scale_logits_by_temperature(logits, temperature):
if temperature <= 0:
raise ValueError("Temperature must be positive")
return logits / temperatureTemperature Effects
Low temperature (< 1.0): Sharpens distribution
- More confident, less random
- Example: T=0.35 → "Berlin" gets 40% probability
High temperature (> 1.0): Flattens distribution
- Less confident, more random
- Example: T=5.0 → More diverse tokens get probability
Temperature = 1.0: No change (original logits)
From Logits to Probabilities
Sampling Instead of Argmax
Step 1: Apply temperature scaling
rescaled_logits = logits / temperatureStep 2: Convert to probabilities using softmax
probabilities = torch.softmax(rescaled_logits, dim=-1)
# Now probabilities sum to 1.0Step 3: Sample according to probabilities
next_token = torch.multinomial(probabilities, num_samples=1)
# Each token has a chance proportional to its probabilityTemperature Sampling Implementation
@torch.inference_mode()
def generate_text_temp_stream_cache(
model, token_ids, max_new_tokens,
eos_token_id=None, temperature=0.0
):
model.eval()
cache = KVCache(n_layers=model.cfg["n_layers"])
out = model(token_ids, cache=cache)[:, -1]
for _ in range(max_new_tokens):
if temperature is None or temperature == 0.0:
# Greedy decoding
next_token = torch.argmax(out, dim=-1, keepdim=True)
else:
# Temperature sampling
logits = scale_logits_by_temperature(out, temperature)
probas = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probas, num_samples=1)
yield next_token
out = model(next_token, cache=cache)[:, -1]Problem: Temperature Alone Isn't Enough
Too Random vs Too Conservative
Low temperature (0.35): Safe, but might miss creative solutions
Generates: "Berlin", "Berlin", "Berlin", "_____", "Berlin"...
High temperature (5.0): Diverse, but can be incoherent
Generates: "mistress", "hot", "daar", "hailed"...
Solution: Top-p sampling (nucleus sampling)
Top-p Sampling
Only Sample from the "Nucleus" of High-Probability Tokens
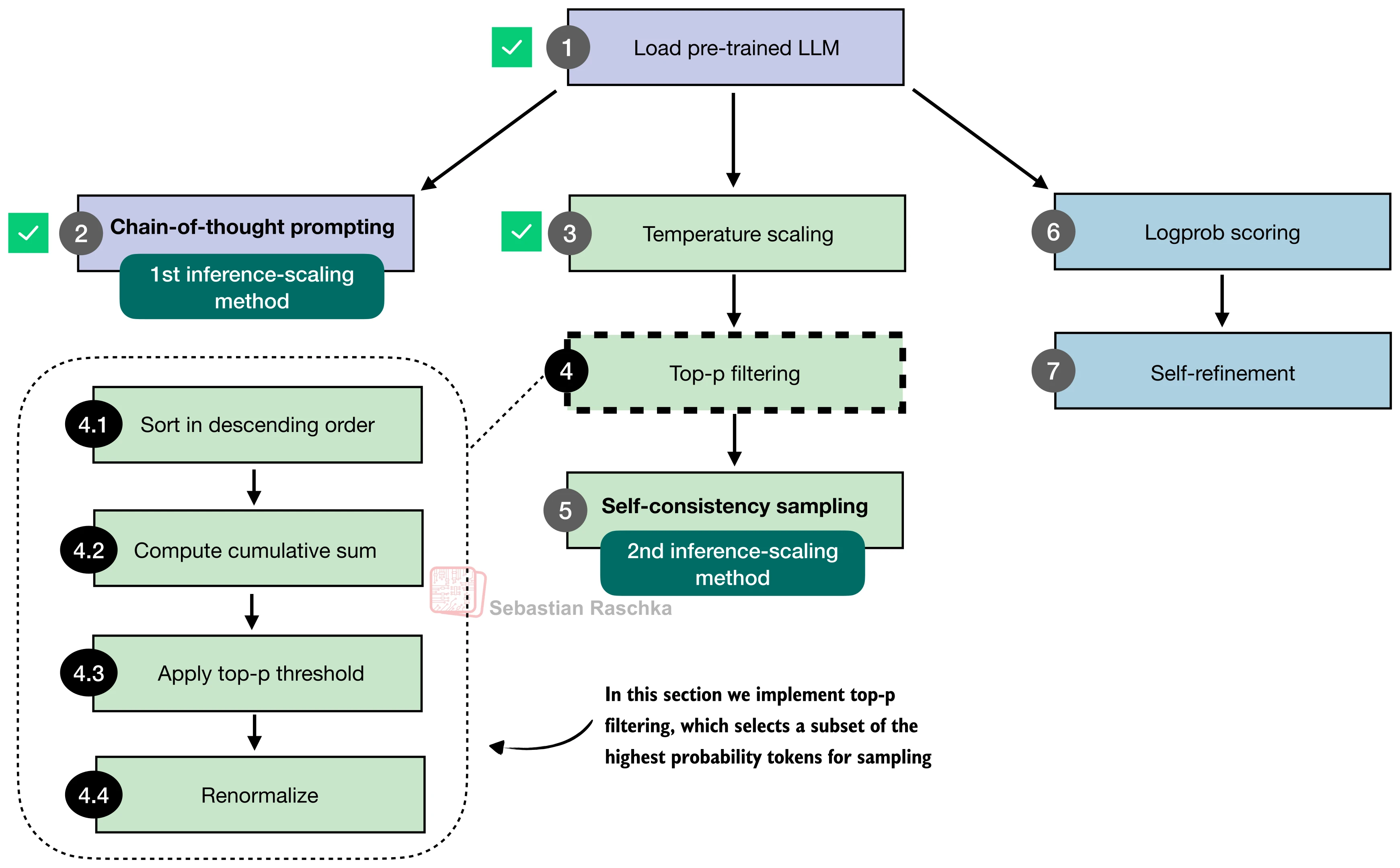
Concept: Only sample from the top tokens whose cumulative probability ≤ p
Top-p Example (p = 0.8)
Token probabilities (sorted):
Token 1: 45.4% → Cumulative: 45.4% ✓ Keep
Token 2: 27.5% → Cumulative: 72.9% ✓ Keep
Token 3: 8.3% → Cumulative: 81.2% ✓ Keep (crosses threshold)
Token 4: 6.8% → Cumulative: 88.0% ✗ Remove
Token 5: 3.7% → Cumulative: 91.7% ✗ Remove
...
Result: Sample only from top 3 tokens, then renormalizeKey Insight: Adaptive cutoff based on probability distribution
- Confident model → Few tokens
- Uncertain model → More tokens
Top-p Implementation
def top_p_filter(probas, top_p):
if top_p is None or top_p >= 1.0:
return probas
# Step 1: Sort by descending probability
sorted_probas, sorted_idx = torch.sort(
probas, dim=1, descending=True)
# Step 2: Cumulative sum
cumprobas = torch.cumsum(sorted_probas, dim=1)
# Step 3: Keep tokens where prefix mass < top_p
prefix = cumprobas - sorted_probas
keep = prefix < top_p
keep[:, 0] = True # Always keep at least one
# Step 4: Zero out and renormalize
kept_sorted = torch.where(
keep, sorted_probas, torch.zeros_like(sorted_probas))
filtered = torch.zeros_like(probas).scatter(
1, sorted_idx, kept_sorted)
return filtered / torch.sum(filtered, dim=1, keepdim=True)Technique 4: Self-Consistency
Generate Multiple Answers, Vote for the Best

The Idea:
- Generate N different answers using temperature sampling
- Extract the final answer from each response
- Choose the most frequently occurring answer
Self-Consistency Voting Process
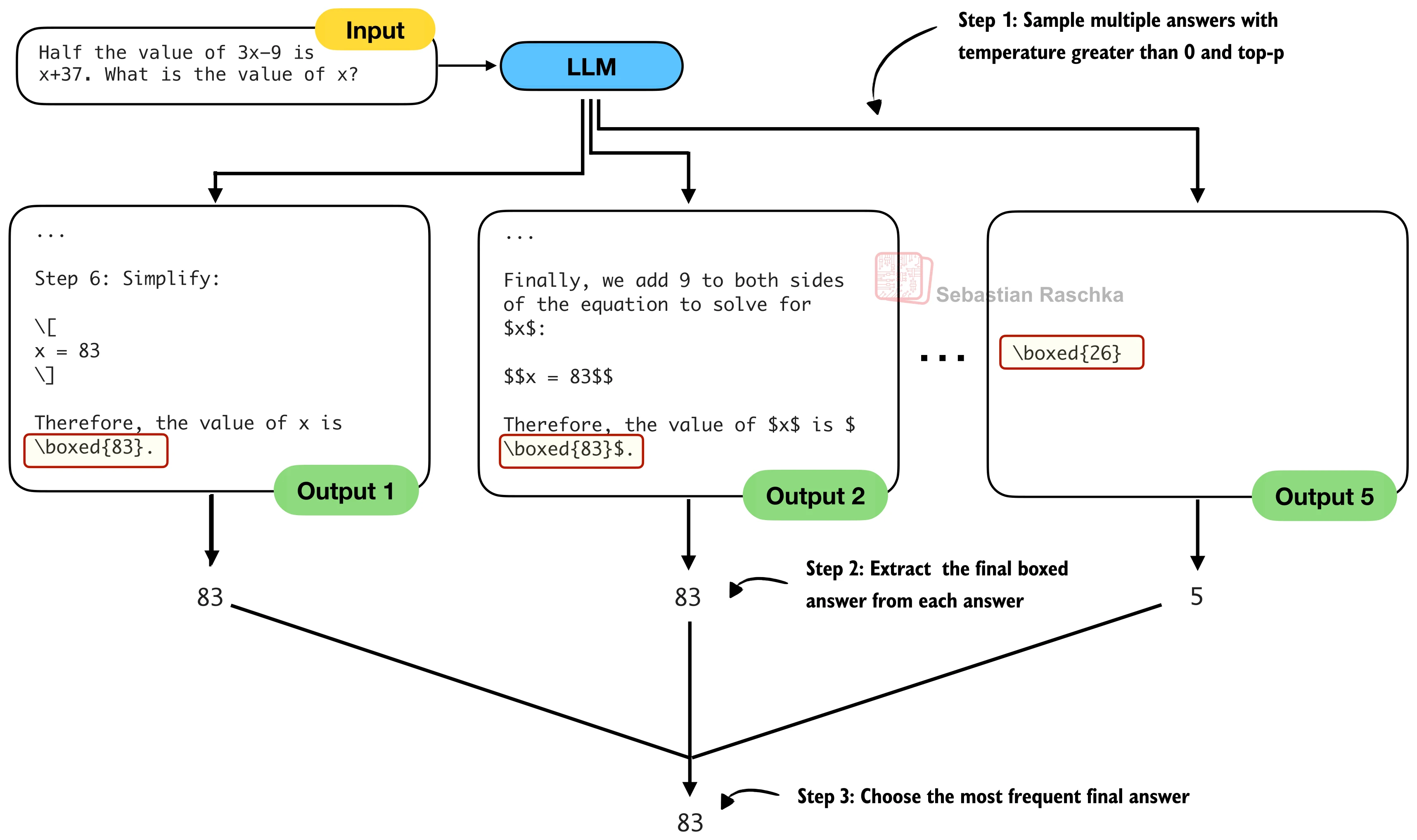
Example with n=5 samples:
Sample 1: (Full reasoning...) → \boxed{83}
Sample 2: (Different reasoning...) → \boxed{22}
Sample 3: (Another approach...) → \boxed{54}
Sample 4: (Yet another path...) → \boxed{83}
Sample 5: (Different mistakes...) → \boxed{61}
Vote Count:
83: ✓✓ (2 times) ← Winner!
22: ✓ (1 time)
54: ✓ (1 time)
61: ✓ (1 time)
Final Answer: 83Self-Consistency Implementation
def self_consistency_vote(
model, tokenizer, prompt, device,
num_samples=10, temperature=0.8, top_p=0.9
):
full_answers, short_answers = [], []
# 1) Sample multiple answers with diversity
for i in range(num_samples):
answer = generate_text_stream_concat_flex(
model, tokenizer, prompt, device,
generate_func=generate_text_top_p_stream_cache,
temperature=temperature, top_p=top_p,
)
# 2) Extract final answer
short = extract_final_candidate(answer)
full_answers.append(answer)
short_answers.append(short)
# 3) Vote: choose most frequent answer
counts = Counter(short_answers)
most_common = counts.most_common()
final_answer = most_common[0][0] if most_common else None
return {
"full_answers": full_answers,
"short_answers": short_answers,
"counts": dict(counts),
"final_answer": final_answer
}Self-Consistency Example Output
results = self_consistency_vote(
model, tokenizer,
prompt + "\n\nExplain step by step.", # Use CoT!
device=device,
num_samples=5,
temperature=0.8,
top_p=0.9
)Console Output:
[Sample 1/5] → '83'
[Sample 2/5] → '83'
[Sample 3/5] → '83'
[Sample 4/5] → '83'
[Sample 5/5] → '83'
Final answer: 83All 5 samples converged to the correct answer!
Results: Method Comparison
All Techniques Benchmarked on MATH-500
| # | Method | Model | Accuracy | Time |
|---|---|---|---|---|
| 1 | Baseline (greedy) | Base | 15.2% | 10 min |
| 2 | Baseline (greedy) | Reasoning | 48.2% | 182 min |
| 3 | Chain-of-thought (CoT) | Base | 40.6% | 85 min |
| 4 | Temperature + top-p | Base | 17.8% | 31 min |
| 5-7 | Top-p + SC (n=3,5,10) | Base | 27.8-31.6% | 98-300 min |
| 8 | Top-p + CoT | Base | 33.4% | 129 min |
| 9 | SC (n=3) + Top-p + CoT | Base | 42.2% | 212 min |
| 10 | SC (n=5) + Top-p + CoT | Base | 48.0% | 453 min |
| 11 | SC (n=10) + Top-p + CoT | Base | 52.0% | 863 min |
| 12 | SC (n=3) + Top-p + CoT | Reasoning | 55.2% | 544 min |
Accuracy vs Computational Cost
Key Insights:
- CoT is the biggest single gain (15% → 40%)
- Diminishing returns with more samples
- 10× computation for 1.5× accuracy
- Sweet spot: n=3-5 samples
Real-World Applications
Modern AI Systems Use These Techniques
Claude 4 (Anthropic, 2025):
- Parallel sampling similar to self-consistency
- Internal scoring model to rank responses
OpenAI o1 (2024):
- Heavy test-time compute scaling
- Extensive chain-of-thought during inference
DeepSeek R1 (2024):
- RL-trained reasoning model
- Still uses inference-time scaling
These techniques are production-critical in state-of-the-art AI!
Conclusion & Key Takeaways
Four Powerful Techniques:
- ✅ Chain-of-Thought - Ask to explain step-by-step
- ✅ Temperature Scaling - Control randomness
- ✅ Top-p Sampling - Adaptive token filtering
- ✅ Self-Consistency - Vote across samples
15.2% → 52.0%
3.4× improvement without retraining!
Thank You!
Resources:
Book: "Build a Reasoning Model (From Scratch)" by Sebastian Raschka